本篇并非系统完整地介绍性能相关的知识,只作为在性能方面给出整体的学习脉络参考。
性能指标
- FCP:First Content Paint,内容首次绘制时间点
- TBT:Total Block Time,总阻塞时长。长任务的阻塞时间是该任务持续时间超过50毫秒的部分,一个页面的总阻塞时间是指在FCP和TTI之间发生的每个长任务的阻塞时间总和
可通过pagespeed、webpagetest、dotcom-tools测试网页加载情况
性能指标不只以上两个指标,详细可访问LightHouse文档进行完整地学习。
构建优化
- 代码分割:运行时主代码、公共模块、第三方依赖单独打包
- 按需加载:按路由拆包、通过静态分析按需导入模块的相关代码
- 若代码使用ESM,则开启tree-shaking(通过静态分析删除导入模块中的无用代码),和scope hoisting(将有依赖关系的多个模块合并到一个函数中,大多打包工具默认开启)
- 资源压缩,包括HTML、CSS、JS、图片、字体、音视频等
网络优化
使用http/2
- 资源占用率低:头部压缩、基于流的多路复用
- 安全性高:TLS保障
https优化
- 链路优化:建立连接的延迟体现在每个SSL连接上,因此尽早完成SSL握手是重点。对于普通的图片资源和文档请求,在CDN上完成;对于涉及用户信息的受限资源和脚本,在内网防火墙上完成
- SSL协议优化:服务端支持ALPN协议,使用适合Forward Secrecy的加密算法,开启False Start,客户端在第二次SSL握手时可以发送应用数据,减少一次RTT时间
- 证书链优化:由于TCP初始拥塞窗口的存在,如果证书太长可能会产生额外的往返开销。移动端采用的证书链是"站点证书 - 中间证书 - 根证书"三级,同时服务端只发送站点证书和中间证书,根证书部署在客户端,将证书链控制在3KB以内。为了避免不必要的证书过期校验,在服务端开启OCSP Stapling
- 加密套件优化:优先选择ECDHE-RSA-AES128-GCM-SHA256,其综合安全、性能和开销,是最优选
控制传输大小和减少请求数
nginx开启gzip,压缩资源大小
还有以下两种方式:
conf# 1、构建时压缩,优先使用预压缩文件 # 1.1、webpack配置插件BrotliWebpackPlugin(brotli压缩)或CompressionPlugin(gzip压缩) # 注意:图片无需压缩;字体文件eot、ttf、svg可压缩,woff/woff2已内建压缩 # 1.2、使用预压缩文件 gzip on; gzip_static on; # 验证:检查etag是否带W/,带则表示nginx实时压缩,未使用预压缩文件js// *2、运行时压缩 // 全局注入方式 const express = require('express'); const compression = require('compression'); const app = express(); app.use(compression()); app.use(express.static('public')); const listener = app.listen(process.env.PORT, function() { console.log('Your app is listening on port ' + listener.address().port); });js// 局部注入方式 const express = require('express'); const app = express(); app.get('*.js', (req, res, next) => { req.url = req.url + '.gz'; res.set('Content-Encoding', 'gzip'); next(); }); app.use(express.static('public'));设置响应头Access-Control-Max-Age,指定预检请求的有效期,减少options请求
过滤请求携带的无用参数
移动端域名收敛,PC端域名发散
- 域名收敛:将静态资源放在同个域名下,提高性能,减少DNS解析开销,多用于移动端
- 域名发散:将静态资源放在多个不同域名(但不是越多越好)下,提高并行度,加速静态资源加载。一般用在pc端,充分利用浏览器多线程并行下载能力
使用HttpDNS寻址
使用HttpDNS可以保证DNS解析安全、快速、精确:
- 根治域名劫持:HttpDNS使用HTTP协议向DNS服务器80端口请求,代替传统的DNS协议向DNS服务器53端口请求,通过IP直连避免解析被篡改,绕开Local DNS
- 降低延迟:本地缓存IP减少解析时间,提升请求速度
- 精准调度:直接获取用户IP,避免DNS出口IP与业务IP不一致的问题
HttpDNS实现原理分为两步:
- 客户端检查本地缓存是否存在或过期,若不存在或过期,则向HttpDNS服务器发起请求(该请求为ip直连请求),获取与域名对应的一系列ip列表;
- 客户端从ip列表中选取访问延迟最优的ip,直接用此ip代替域名发送请求,并更新缓存,若获取失败则降级使用Local DNS域名解析
缓存优化
热点缓存
访问频率高的页面静态化;Redis缓存热点数据
CDN缓存
若请求资源未过期,则返回304,否则CDN根据浏览器提供的域名,通过内部专用DNS解析此域名的IP,再向此IP地址提交访问请求。从实际IP地址获取资源响应后,一方面在本地进行保存,以备后用,另一方面将资源响应返回给客户端
使用强缓存和协商缓存
重复请求检测,复用响应结果
部分更新下的缓存处理
revving技术属于覆盖式发布。若静态资源和页面属于分开部署,可能先部署页面再部署静态资源,会出现用户访问到旧的资源,也可能先部署静态资源再部署页面,会出现没有缓存用户加载到新资源而报错,以上本质上都是覆盖式发布惹的祸。所以静态资源需要非覆盖式发布,即用静态资源的文件摘要信息给文件命名,这样每次更新资源不会覆盖原来的资源,先将资源发布上去,这时存在两种资源,用户用旧页面访问旧资源,然后再更新页面,用户变成新页面访问新资源,就能做到无缝切换。目前比较流行的是给文件名加
content-hash
交付优化
从浏览器渲染引擎特性角度优化:
特性1:JS执行会阻塞DOM和CSS OM构建
JS执行会造成阻塞是因为JS可能操作DOM
优化措施
- 当脚本不影响渲染逻辑,可以进行异步加载,浏览器提供了defer和async两种方式
共性特点优先级选择async允许下载脚本时进行DOM渲染,说明下载是异步操作的无序性,只要js引擎可用立即执行,无需等待文档就绪。
从该特性上看出,易引起海森堡蚁虫之灾,即脚本加载结束后出现各种问题,仅适于独立脚本async > defer根据脚本是否是独立,若是则用async,否则用deferdefer延迟性,需等待文档就绪才可执行;
顺序性,需所有前面具有defer属性的脚本结束运行才可执行。
从这两个特性上看出,defer既有将脚本置于body标签的全部好处,又使文档加载速度大幅提升。- 脚本置于HTML文档尾部,提前触发首次绘制时间
特性2:CSS执行不阻塞DOM构建,但会阻塞JS
HTML解析和CSS计算是采用流水线处理,另外会阻止JS运行,其原因是JS可能对CSS有依赖
优化措施
- 样式置于HTML文档头部,提前首屏渲染时间
- CSS文件按媒体类型拆分,浏览器根据link标签media属性加载对应样式
- 首屏避免使用导入样式@import,该方式是串行加载执行,无法并行调用,使用内联、嵌入或链接样式替代
- 通过CSS继承提高代码复用性
从用户体验角度优化:
- 减少白屏等待时间
- 添加loading或转场动画
- 使用骨架屏
从渲染路径角度优化:
- 最小化主线程工作:抓住关键渲染路径(即HTML、CSS、JavaScript之间的依赖关系谱)影响因素,优化路径,缩短加载时间
内联关键CSS、JS
预加载
preload,用于公共资源,本页面会使用的资源prefetch,用于可能访问的下一页面资源,跳转其他域名或请求其他域名的资源dns-prefetch、preconnect等,建立与所需来源的早期连接懒加载
图片懒加载:先占位,待元素可见(借助
IntersectionObserver)再加载资源地址长列表滚动加载
使用动态导入延迟加载,一般用在非关键流程代码上
从架构角度优化:
- 架构升级
- 预渲染
- 同构
- PWA
图片优化
属于交付优化在图片上进行的处理。
- 大图提供不同分辨率的图片,根据设备像素比,或网络情况,或设备信息,展示相应图片
- 小图使用雪碧图(CSS Sprite,将多张小图拼成一张合成图,再通过
background-position属性进行定位。被合并的资源越小,请求时长越短的效果越明显),或base64内嵌,或纯CSS实现,减少请求数 - 非关键图片使用懒加载
- 图片格式选择优先级:SVG > WEBP > JPG > PNG
- 低清晰度图片使用锐化,提升体验
渲染优化
先认识Chromium渲染原理。
一帧做的事情: 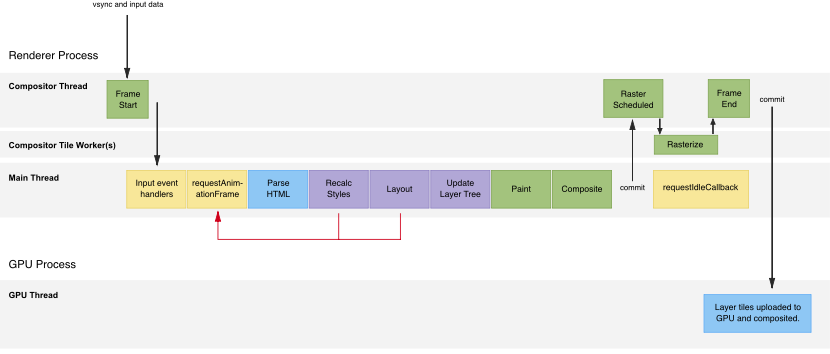
一帧中主线程做的事情: 
下面根据渲染过程的每一步分别针对性优化:
1)JS执行
- 避免在事件处理函数执行长任务,确定优先级,分步执行,通过异步(这里用宏任务处理,若当中涉及DOM操作,则该部分在微任务处理,避免渲染不连续出现闪烁,或布局抖动,或数据不一致)或线程实现处理,防止页面阻塞和布局混乱
2)样式计算
降低其范围和复杂度
- 避免使用复杂选择器,层级越少越好
- 减少需要执行样式计算的元素个数
- 避免使用标签选择器和通配选择器
3)布局
避免其大规模、复杂化,其耗时取决于布局的DOM元素数量及其复杂程度
使用新式布局如flex、grid,代替table、float等旧布局
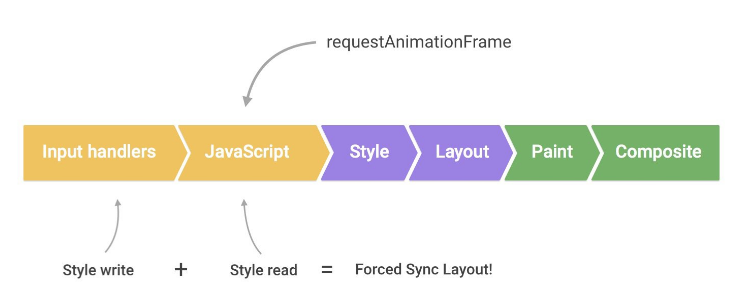
避免强制自动重排,可以缓存相关属性值或方法结果,避开读操作
javascript// 相关属性或方法: // clientTop、clientLeft、clientWidth、clientHeight、 // offsetTop、offsetLeft、offsetWidth、offsetHeight、 // scrollTop、scrollLeft、scrollWidth、scrollHeight、 // computedStyle、currentStyle // getBoundingClientRect() // 先写后读,触发强制自动重排 function triggerStyleCalcAndLayout() { // 更新box样式 box.classList.add('super-big'); // 为了返回box的offsetHeight,浏览器必须先应用属性修改,接着执行布局过程 console.log(box.offsetHeight); } // 先读后写,避免强制自动重排 function notTriggerStyleCalcAndLayout() { // 获取box.offsetHeight console.log(box.offsetHeight); // 更新box样式 box.classList.add('super-big'); }强制自动重排示意图:
通过
classname一次性改变样式,避免频繁操作样式脱离文档流,在内存中操作DOM,避免频繁操作DOM:如创建文档片段
document.createDocumentFragment进行操作再替换,或克隆节点cloneNode进行操作再替换,或display:none隐藏后进行操作再恢复显示动画元素添加
position:absolute,避免修改样式时回流
4)绘制
- 提升移动或渐变元素的绘制层
- 减少绘制区域
- 简化绘制复杂度
- 通过计算和判断,避免无谓的绘制操作
动画优化
不同动画实现的差异
性能(从表现上看是否丢帧):开启GPU的CSS动画 > 普通CSS动画 > JS动画
可控性:JS动画可控,CSS动画难以控制
浏览器对每一帧的渲染工作要在16ms内完成,超出该时间则称为丢帧,一般控制帧率不超过60fps。 帧率,即每秒帧数。帧率对于人眼是在50-60,若帧率低于30,称为卡顿(连续出现3个低于20fps),若高于60则太快,俗称“亮瞎”。
javascript// 实时计算帧率 (function(){ const raf = (function(){ return window.requestAnimationFrame || window.webkitRequestAnimationFrame || function(callback) { window.setTimeout(callback, 1000 / 60) } })() let frame = 0 let allFrameCount = 0 let lastTime = Date.now() const loop = function() { raf(loop) const now = Date.now() frame++ allFrameCount++ if (now - lastTime > 1000) { console.log('帧率:', Math.round(frame / ((now - lastTime) / 1000 )), '帧数:', allFrameCount) lastTime = now frame = 0 } } loop() })()我们一般遇到的都是卡顿问题。
频繁但较小的卡顿:主要原因是过高的渲染性能开销,在每一帧中做的事情太多,参考下面介绍的优化调整代码,甚至降低动画复杂(炫酷)程度。
较大但偶发的卡顿:主要原因是运行复杂算法、大规模DOM操作等,考虑使用
requestIdleCallback、worker、offScreenCanvas等。CSS动画优化
使用
transform代替top、left实现动画,避免回流、重绘应用3D转换、
opacity、filter或will-change,开启GPU加速各大浏览器也提供了相应的Animation API,可控性更好
JS动画实现方式
requestAnimationFrame动画实现相对于setTimeout有三大优势:
防丢帧:setTimeout的执行步调与屏幕的刷新步调不一致,会丢帧。而requestAnimationFrame最大优势是由系统决定回调函数的执行时机,它能保证回调函数在屏幕每次刷新间隔中只被执行一次,不会引起丢帧,但注意控制回调任务的执行时长。
节省CPU开销:默认情况下,使用setTimeout实现的动画,当页面被隐藏或最小化时,setTimeout仍在后台执行,浪费CPU资源。而requestAnimationFrame则不同,当页面未激活,页面的屏幕刷新任务会被系统暂停,因此跟着系统步伐走的requestAnimationFrame也会停止渲染。
回调节流:在高频率事件如resize、scroll中,使用requestAnimationFrame可保证每个刷新间隔内,函数只被执行一次。
Canvas动画
复杂动画可以考虑使用Canvas动画,代替DOM动画。以下是使用Canvas实现动画时的可供参考的优化手段:
尽可能减少调用渲染相关API的次数,尽可能调用渲染开销较低的API
比如执行
context.lineWidth = 5,浏览器需立刻做一些事情,以便调用如stroke或strokeRect时,绘制的线宽正好5个像素。,它的赋值操作开销远大于对一个普通对象赋值的开销。再者,putImageData也是一个开销极为巨大的操作,不适合在每一帧里面去调用。下表是不同属性的赋值开销。
合理地调整调用绘图API顺序,降低context状态改变的频率
采取Canvas分层
生成多个Canvas实例,把它们重叠放置,每个Canvas使用不同z-index定义层级,然后在相应的canvas层进行重绘。
将渲染阶段的开销转嫁到计算阶段之上
使用
drawImage绘制同样大小的区域,数据源是一张和绘制区域尺寸相仿的图片的情形,比起数据源是一张较大图片的情形,前者开销要小一些。可以认为,两者相差的开销正是裁剪这一操作的开销。优化思路是将裁剪这一步事先做好,保存起来,每一帧中仅绘制不裁剪。离屏绘制
drawImage方法的第一个参数不仅可以接收Image对象,也可以接收Canvas对象,使用Canvas对象绘制的开销与使用Image对象的开销几乎完全一致
var offScreenCanvas = document.createElement('canvas');
offScreenCanvas.width = dw;
offScreenCanvas.height = dh;
offScreenCanvas.getContext('2d').drawImage(image, sx, sy, sw, sh, dx, dy, dw, dh);
context.drawImage(offScreenCanvas, x, y);内存优化
前面介绍的渲染优化一般是从时间复杂度方面入手,而内存优化从空间复杂度上实现渲染间接优化。
当事件处理程序尚未执行结束,则不触发
针对大量相同事件类型,可考虑使用事件委托
防止内存泄漏,可以从以下方面进行检查:
1.使用闭包,需及时赋值为null
2.意外的全局变量,为变量选择合适的作用域
3.脱离的DOM节点,如删除的节点、只在内存中使用的缓存节点,及时赋值为null
4.console.log打印的对象,生产环境避免使用它
5.定时器未及时清除
6.事件处理器未及时删除
如何定位?无痕模式(屏蔽Chrome插件对测试内存占用的影响)打开Chrome,打开开发者工具,找到Memory,记录复现过程中内存占用情况
小结
本篇从构建、访问(网络或缓存)、加载,到渲染的一个顺序,总结了各过程常见的优化手段。但是性能优化绝不仅于此,随着开发者涉猎越广,其可优化之处越多,是一个没有终点的过程。我们目前只需先定位性能问题在整个链路中哪个环节里较为突出,进行重点改进,其余环节为辅,最后可以通过上面提供的性能指标评测网站检验优化效果。